At Seccl we’re using APIs to rebuild the infrastructure of investments and advice, and help forward-thinking advisers and disruptive fintechs to build the innovative investment platforms of the future.
Our APIs are used by a growing number of clients to power a fast-rising volume of investments and, unsurprisingly, we’re constantly developing and deploying new features.
While there are plenty of factors that can affect the pace and efficiency of our deployment cycles, automated testing is a big one. In fact, it’s absolutely key to us being able to release new changes at speed and with confidence.
Recently, we moved across 25 tests from a Postman/Newman infrastructure and, in the process, created around 100 tests in our new infrastructure. In this article I’ll explain why, how and what impact it’s had on our development process.
The way things were
We use Postman as a UI for interacting with our API and to create API docs. It allows you to store login tokens and other environmental variables – which is handy when working with multiple requests. It’s also great for manual testing and creating dummy data for things super quickly.
Until recently, we also created and managed our end-to-end tests inside a Postman collection, too. Although this gave us some automated testing coverage, it wasn’t the optimal approach, for several reasons.
Wait, Mr Postman…the problems we faced
-
No independence: most of the tests weren’t independent and relied on previous tests in the run to complete and save data. For example, one test would create a client and then save that client id to the ‘environment’ as a global variable, and then a later test would use that client id to create an account). As well as making refactoring a nightmare, this also meant that if one test failed, then all subsequent ones would too – making the tests hard to debug and slowing down deployments.
-
Frustrating developer experience: the Postman UI is OK for throwing together API requests, but for writing complex tests it isn’t ideal. It doesn’t offer the same experience that an IDE like Visual Studio or WebStorm would.
-
Challenging to manage mock data: the mock data for tests had to live inside the ‘Pre request’ script (it couldn’t just live in a separate file) section of the Postman tab, which wasn’t ideal.
-
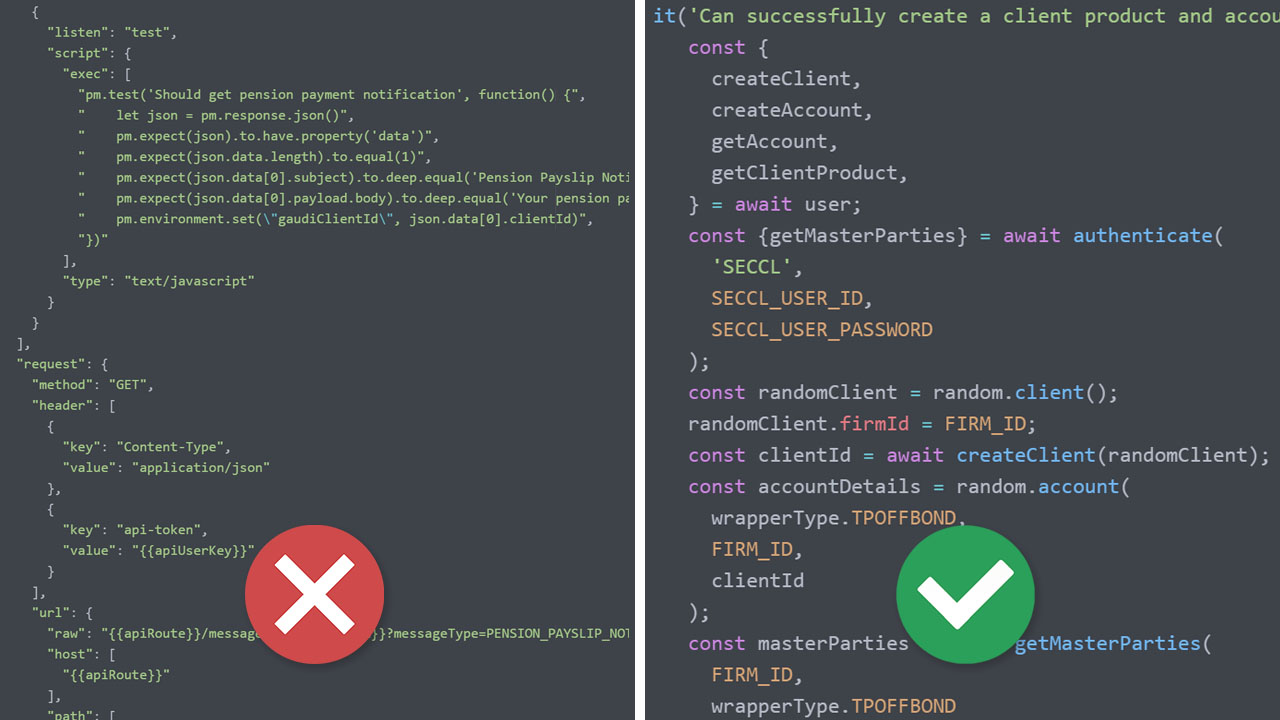
Managing PRs: we use GitHub as the central repository for the Postman tests. However, the process for getting the Postman tests into GitHub involves exporting a massive JSON file; the resulting PR ends up being a comparison between two big JSON files with loads of boilerplate code.
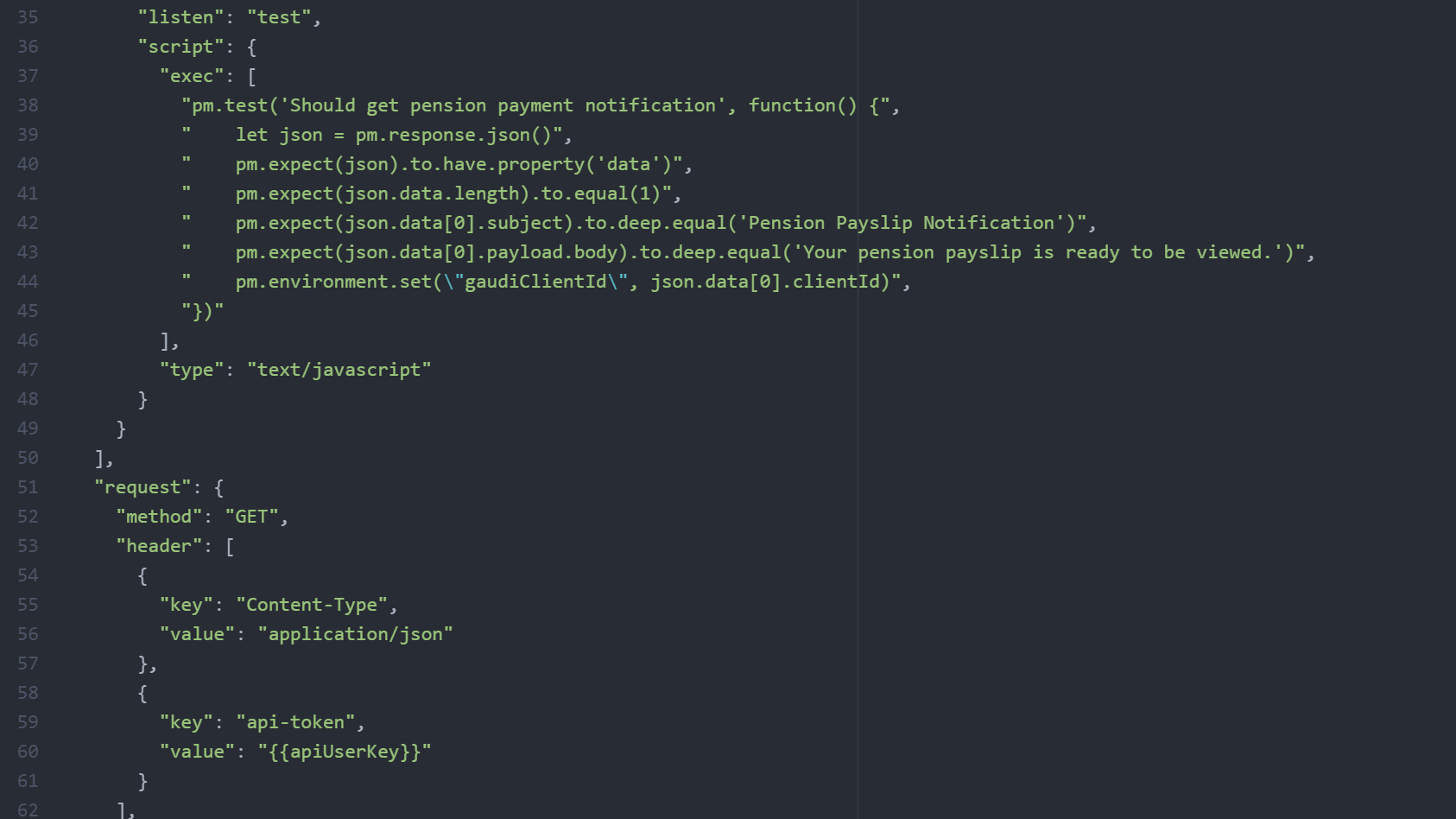
PR for adding a new test with old stack (Postman)
Developing a solution
We had known for a while that we wanted to migrate to a better solution, and earlier this year we dedicated a six-week development cycle to migrate the tests over to a new framework.
Some of our QA team started by analysing and rewriting each of the Postman tests into BDD syntax, to spot where there were overlaps, understand where dependencies existed between the old tests, and create an easy way for us to write the new one and track our progress.
At the same time, several developers set about researching and experimenting with the underlying infrastructure and core machinery that the tests would sit on top of.
After that, we worked hard to rewrite the tests, with both developers and QA engineers writing code in the new framework.
The new stack
So what framework is that, exactly?
-
We have a single Git repo, organised into data, test and infrastructure.
-
The tests are written in TypeScript (like most out our front- and back-end code bases) which give us extra control and confidence when building at speed.
-
We use Jest as the test runner and assertions library. With the Postman tests, we were using raw JavaScript to check equality, which gets messy and can produce runtime errors – while Jest’s really useful expectation errors provide a neater solution.
-
We use a tool called Got for calling the API. It’s a really nice abstraction but still gives us lots of control (for example of error logging)
-
We use quite a bit of ramda, a functional JavaScript testing library (more on this below).
The benefits
This was a really worthwhile investment of time and we’re already seeing the benefits. In particular…
-
It’s now far quicker to create new tests. We created a new ‘SDK’ for the core infrastructure used in the tests (for example creating clients or creating accounts), all of which is reusable across different tests. By reusing code, we’re massively reducing the amount of time that it takes to create new tests.
-
Reviewing tests is much faster. Previously, the tests were in JSON format – and comparing PRs which are diffs of JSON files is not easy. A test that would have been 50+ lines of messy, nested JSON is now 15 lines of clean JavaScript code.
-
The tests are far more reliable. Because each test is independent of all others – and because we have set up sophisticated polling (and avoided flakey timeouts like in the Postman tests) – we have more reliable tests that fail far less frequently. This gives us much more confidence with our deployments.
-
We have far more control over error handling. When tests do fail, either when writing new tests or as part of a scheduled run, we now have far more control and visibility over the error messaging. We have configured Got to throw helpful diagnostic messages that show the failed request, so that we can inspect the database to diagnose what’s gone wrong. Meanwhile, at a more granular level, we can use Jest’s expect function to clearly show the difference between what was passed into a test and what was expected (instead of just seeing a reported runtime error). These both make it far quicker to understand broken tests and fix them.
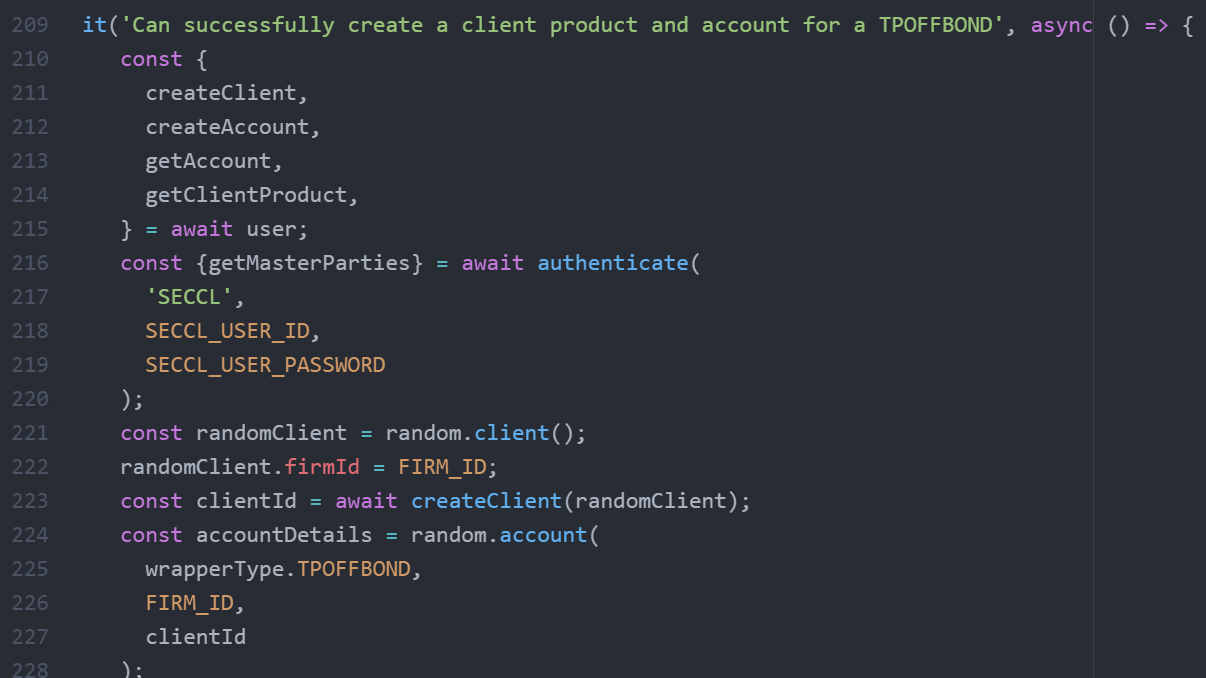
PR for adding a new test with new stack (Jest)
Some challenges
Inevitably there were some challenges along the way, the biggest one being testing asynchronous workflows.
By way of context, some parts of our API involve some asynchronous processing because of the way we use queues. For example, a test that creates a client, then an account, then sets up a payment, before confirming that payment and checking the payment has landed in the account…that doesn’t happen synchronously, so it’s not easy to work out of it has all been successful.
The solution was to create some reusable infrastructure for polling. We used the functional JS library ramda as really compact and neat way of creating rules to determine when the polling is done in a maintainable way.
Final thoughts?
It was a difficult process, but well worth the investment of time. We’re now adding new system tests alongside our development work at a much higher rate than before, and we spend much less time and energy dealing with failed tests.
All of which makes our process for deploying new and critical client functionality faster and more effective.


