Introduction
At Seccl we’re actively encouraged to spend part of our time at work learning new things, and we’re lucky enough to have a company Udemy account to help us do so. One of the things I’ve been learning about recently is GraphQL. I thought I’d share some of what I’ve learnt so far.
This article will cover:
-
What is GraphQL?
-
Why was GraphQL created and what problems does it solve?
-
How do I implement GraphQL?
-
What projects is GraphQL useful for?
-
Summary
-
Further reading
What is GraphQL?
The simple definition
GraphQL is a modern approach for transferring data between a client (e.g. a mobile app front-end or a browser) and a server (e.g. the web server serving a website). It allows the client to control and specify the structure of the response it expects from the server.
This is different from other approaches. A very common approach for client-server data transfer is based on REST, where the server controls the shape of the data sent to a client. The RESTful style is the ‘typical’ method that client-server architectures use in modern web apps – at least in my experience.
The precise definition
That’s the simple definition. To be more precise, GraphQL is a specification for a query language used by web service APIs, and a runtime specification for using those queries to fetch data.
So it has two components: a specification for how a client requests data, and another for how servers handle a request and return a response.
The important bit is that it’s a specification – meaning GraphQL can be implemented in different languages and using different frameworks, so long as the implementation conforms to certain rules.
What is this ‘graph’ thing all about?
GraphQL gives a client the power to specify the structure of the data returned by the server. This is where the ‘Graph’ in GraphQL comes from: the client effectively specifies a graph-like structure for the response it expects.
When I first heard about GraphQL I assumed it was related to Graph databases but actually GraphQL is agnostic to the technology and databases used (on both the client and the server!).
Some history
It was created by Facebook to solve the problems that they ran into trying to scale Facebook.com using the RESTful approach. They wanted a solution that made it easy for their product team and front-end developers to build mobile clients that could request only the necessary data, in a way that was easy to learn and quick to implement. Although it was originally used internally by Facebook, it was made Open-source in 2015.
From what I gather Facebook still use it to this day – as do lots of other organisations.
GraphQL queries
To fetch data from a GraphQL server your client-side code uses a GraphQL type to make a query to the server. This basically tells the server “I want this data and I want it in this format”.
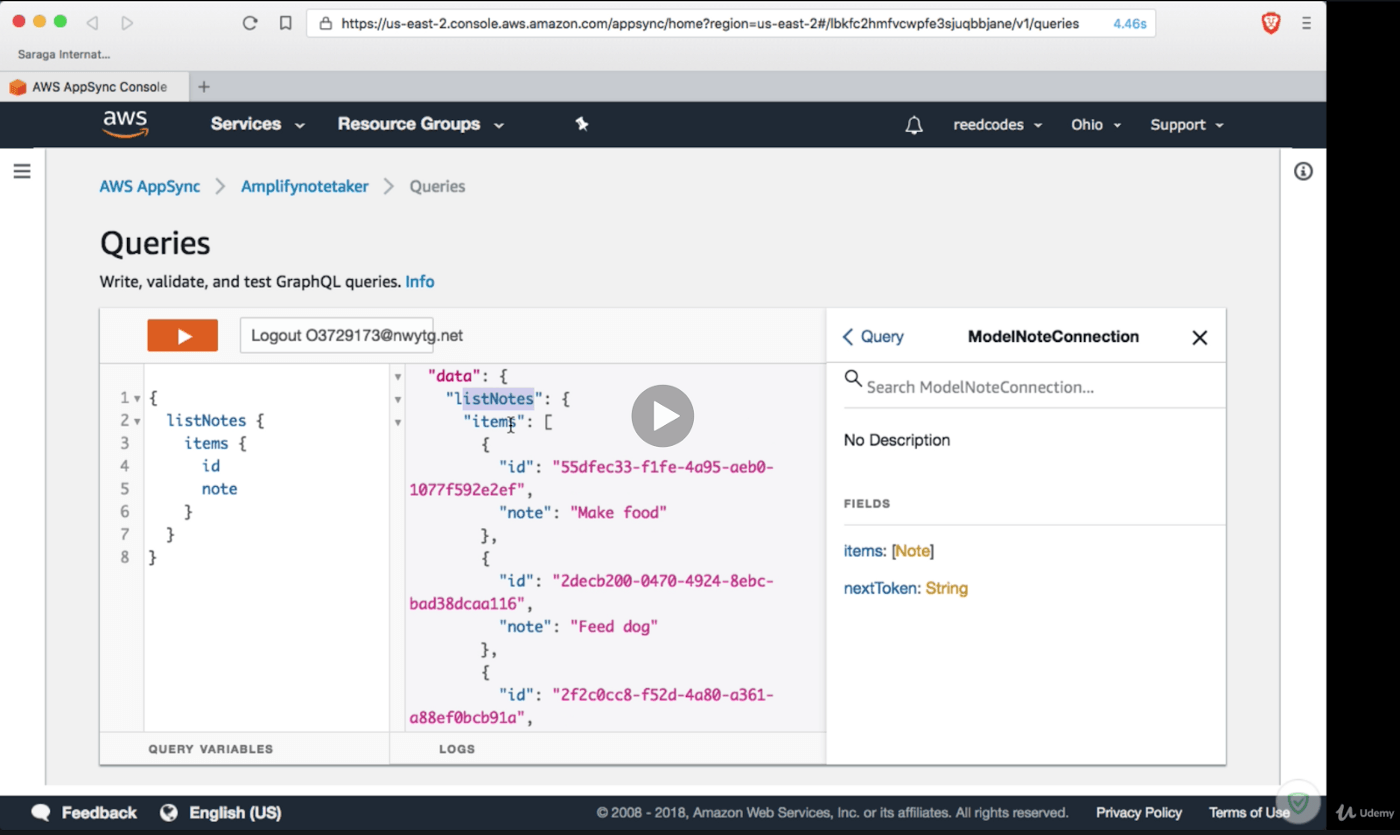
Below you can see an example from the Udemy course I’m following. Part of the course explains how to use AWS App Sync to test GraphQL queries against your data, using Amazon’s console.
On the left you can see the body of the query that’s used to get back a list of ‘notes’ for a note-taking app – while the data returned by the GraphQL server is in the middle panel. You can see that the data is returned in the structure that’s specified by the request.
GraphQL mutations
For a client to create, update or delete data on the backend, you run what’s called a mutation. A mutation takes an instruction and also a graph structure (similar to a query).The instruction is used to create/update/delete data and then the graph structure is used to control the shape of the response returned by the server.
This is useful as you may want to display the information that has just been modified to the user when the server responds with a success message.
Again, the client is controlling the shape of the response from the server.
Why was GraphQL created?
GraphQL gives the client control over the shape of the data returned from the server. This is different to a typical RESTful approach where the server determines the shape of the data that is sent to the client.
The best way to understand why GraphQL was created is to understand the problems that it can solve. Below are some of the challenges that a typical RESTful architecture can present, and some of the solutions that GraphQL can offer.
Reducing client-side data processing
You may support different types of clients accessing the same server. For instance, you may have a web app and a mobile app, both of which want to access your servers.
With the RESTful approach, the client may not get back data in the format it needs to consume. This means the client-side code may have to do some selection, filtering and looping to process the data. All of this will use the processing power of the device and this could impact performance – especially on a low-powered device like a mobile.
Using GraphQL, the client would send a request which specifies exactly what data it would like and the shape that data should be returned in.
So, using GraphQL can reduce the amount of processing required by the client - which can potentially improve the maintainability of the code (by having less of it!) and noticeably improve the performance of your app.
Reducing network request size
I’ve already explained that using a RESTful approach to returning the data you need could actually involve receiving lots more that you don’t need, too. This redundant information means the size of the network request could be bigger than it needs to be. Using a GraphQL approach, you can potentially improve the network footprint of your app – which, again, could improve performance.
Removing request dependencies
A common feature in social media sites is to display a list of comments on a post. You could do this using a RESTful architecture approach, by…
-
Fetching a list of all users by making a request to the
/usersendpoint -
Using the user’s id to fetch a list of all their posts by making a request to the
/posts/:useridendpoint -
Using the id of a particular post to make a request to
/posts/:postid/commentto get the comments for a post with ‘postid’
This approach creates a dependency between requests because we have to wait for each of the previous requests to return successfully before we can fire off the next request. And this poses a number of challenges for developers. For example:
-
how do you write maintainable and clear code that deals with this asynchronous dependency?
-
how do you handle one of those requests failing but not the others?
(Not to mention the extra overhead of making multiple network requests which, you guessed it, can impact performance.)
GraphQL can potentially remove some request dependencies.
Instead of making several dependent requests to get the comments on a post, the client-side code could send a request to the GraphQL endpoint on the server, with the shape of the data the client needs. It could look something like this:

You can see the difference in approach from the diagrams below: with the GraphQL approach there’s only one endpoint exposed (/graphql) and, given a user’s id, only one request has to be made to get the posts for a particular user.
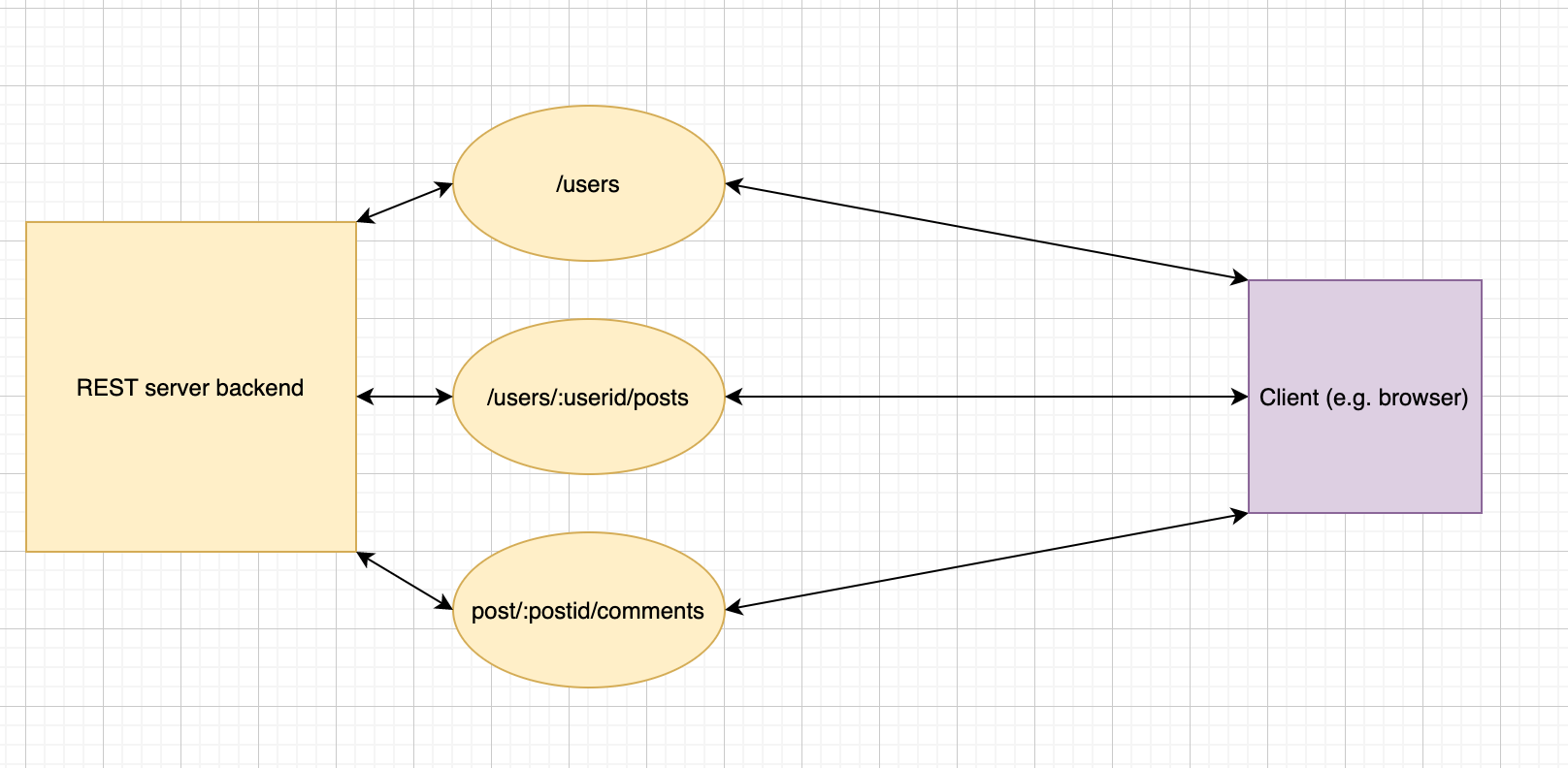
RESTful architecture — all requests from top to bottom must be made to access comments on a post
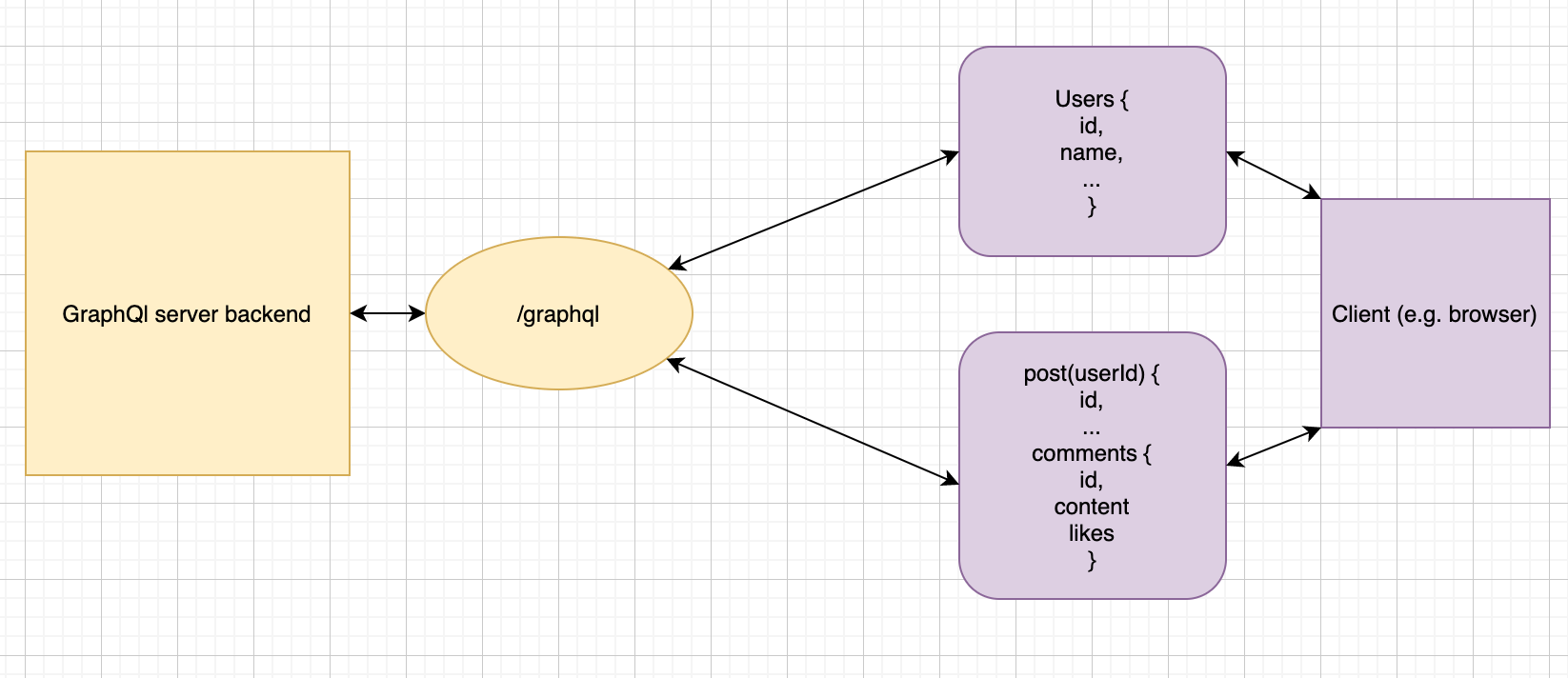
With GraphQL only one request is needed to get the comments on a blog post (given the user’s id)
Reducing the number of network requests
Following on from the example above, a RESTful approach can involve more network requests. This can have significant performance implications for your app, especially if the user has poor network connectivity. With GraphQL, you only need to make one request – so, again, GraphQL could improve the performance of your app.
Fewer endpoints to manage
From a client’s point of view, endpoints are like the gateways to accessing data. In the example above, we saw how with the RESTful approach we needed to manage more endpoints than the GraphQL approach. So, using GraphQL can reduce the amount of publicly-exposed access points, which can make your server code more maintainable – and also reduce the documentation burden on your team.
Increased flexibility
Migrating your API to a newer version is challenging with the RESTful approach, because you need to modify both the client and the server.
An API change could require you to modify how the backend creates the request, and also how your client selects and processes the data that it returns. And changing two places at once creates a coupling between the two different areas of your system, which can make it harder to get right (and also just adds more work).
With the GraphQL approach, the client is more of a consumer. It always gets back data in the shape it wants, which can mean that you don’t need to modify a client at all in response to an API change.
How do I implement GraphQL?
As mentioned above, GraphQL is a specification for a client-side query language and a server-side runtime to handle those queries. Importantly, it is just a specification – in other words a set of rules – and there are lots of specimen-compliant GraphQL solutions to choose from.
The client
There are several different libraries to choose from for the client-side part of GraphQL, and lots of the popular choices also offer a state management solution as well. This means they’ll also automatically handle things like caching, so you only need to fetch data from a server when necessary.
The two most popular solutions seem to be Apollo and Relay. It is actually possible to not use any GraphQL client and just use something like fetch (the in-built browser API for making HTTPs requests) as long as your server supports GraphQL. But the main benefits of using these solutions compared to using (or misusing?) something like fetch is the ease of integration and caching.
A detailed comparison of the two solutions is out of the scope of this article, but an interesting thing to note is that Relay is designed only to work with a React codebase (unsurprisingly as it was created by Facebook, who are also dogfooding React) – whereas Apollo is framework agnostic.
GraphQL server
You’ll need some way for your server to handle the GraphQL queries that come from your GraphQL client. A specification-compliant solution contains what are called resolvers, which handle different types of queries that access and prepare data to be sent back to the front-end (in the format specified by the request from the front-end).
Resolvers are sort of like big switch statements — given a query (e.g. ‘getNotes’) or a mutation (e.g. ‘deleteNote’) they will resolve the query/mutation by selecting the appropriate handler and then fetching/processing data as necessary. The data can be fetched from a database, it can be generated on the server, or it can be fetched from some other endpoint (GraphQL or RESTful or whatever!).
So from a server-side perspective, not much is different from REST. The main differences are that the server now has to structure the data it returns to be exactly as is specified by the front-end (which is coordinated by a type system shared by the client and the server), and that all GraphQL traffic goes through a single endpoint.
One popular solution is Apollo Server and, interestingly, you don’t have to use the Apollo Client for your GraphQL client in order to use it.
What projects is GraphQL useful for?
GraphQL can improve the performance of data-intensive UIs, where performance of client-side code is a big consideration. For instance, Facebook has billions of users on low-powered mobile devices – many of whom might also have a poor internet connection – so the performance of the client is definitely a big factor.
It’s also useful if a product has multiple different clients (e.g. mobile, web app, VR headset) accessing the same server, because the amount of client-side code to process data can be massively reduced – meaning the UI team can develop faster and more easily. This could suit start-ups with limited UI or product resource.
Summary
GraphQL is a solution to handle fetching data for a client from a server. It’s a specification for a server-side runtime and a query language, and there are multiple different solutions for both the client-side part and the server-side part.
GraphQL solves many of the common challenges that are found in a typical RESTful architecture, particularly for data-intensive web apps where lots of complex data requests are made by the client. The main difference between GraphQL and REST is that with GraphQL the client specifies and controls the shape of the data it requires.
The main projects that GraphQL can benefit are those where a client works with a lot of data and is really responsive, as well as products where you need to support multiple clients.
Further reading:
- https://graphql.org/
- https://engineering.fb.com/core-data/graphql-a-data-query-language/
- https://blog.bitsrc.io/apollo-and-relay-side-by-side-adb5e3844935
- https://www.prisma.io/blog/relay-vs-apollo-comparing-graphql-clients-for-react-apps-b40af58c1534
- The GraphQL section of this Udemy course
- AWS App sync Udemy course


